

Stop Retrofitting Your Website for AI
Last month, a CMO I respect showed me an invoice. Six figures. The deliverable: an agency “AI-optimizing” her website. Schema markup. Meta tag rewrites. Long-form content. Technical updates to make the site “AI-friendly.”
She was proud of the investment. I didn’t have the heart to tell her she’d just paid to rearrange furniture in a house that’s invisible to the guests she’s trying to impress.
She’s not alone. There’s a cottage industry telling brands to retrofit their websites for AI. Add structured data. Rewrite copy for LLMs. Optimize, optimize, optimize.
It’s bad advice. Expensive bad advice. And it’s solving the wrong problem entirely.
Here’s the thing nobody wants to say out loud: your website was never built for machines. It was built for humans. Trying to make it work for both audiences is like rewriting a novel so it also functions as a database. You’ll end up with something that fails at both.
The Comprehension Gap Is Structural, Not Cosmetic
The numbers tell the story. ChatGPT has surpassed 800 million weekly active users. AI-powered search is growing 357% year-over-year. Gartner’s 2024 forecast projects a 50% drop in traditional search traffic by 2028. McKinsey’s October 2025 research found that half of all consumers now use AI-powered search tools.
Welcome to the Answer Age. And the infrastructure isn’t ready.
The Everything Machines are already at your door. We’re tracking over 15 distinct AI crawlers — GPTBot, ClaudeBot, PerplexityBot, Gemini-Deep-Research, and more. (The list grows monthly.) And here’s the problem: most of them cannot execute JavaScript.
That means every modern website built on React, Next.js, Webflow, or Squarespace is essentially invisible to the AI systems that increasingly determine how your brand shows up in the world. Commercially invisible.
Using our EverythingScore methodology, Webflow sites score 40–50 out of 100. Squarespace? 35–45. The irony is almost poetic: the prettier the site builder, the worse the machine comprehension.
This isn’t a bug you can patch. It’s the Comprehension Gap — and it’s structural. Your website renders content in the browser using JavaScript. AI crawlers read the raw HTML your server sends before any JavaScript runs. They’re looking at a different version of your site than your customers see. Often, that version is empty.
So when someone tells you to “optimize your existing site for AI,” ask them: optimize which version?
Why Retrofitting Fails
Ignore all of this and try to retrofit anyway. Here’s what you’re signing up for:
You’ll never escape the architecture you started with. Your CMS was designed around visual layouts, not structured data feeds. Every “AI optimization” you bolt on has to work within those constraints.
You’re risking your existing SEO. Search Engine Journal’s analysis of 892 website migrations found that 9 out of 10 damage SEO. Average recovery time? 523 days. And 17% of sites never recover — even after 1,000 days.
The cruel irony: Google’s own John Mueller confirmed in April 2025 that structured data doesn’t boost search rankings. It powers rich snippets — that’s it. So you’re risking proven organic traffic for a schema layer that doesn’t help you rank and still doesn’t solve the fundamental JavaScript problem. Worse, Google actively penalizes misused structured data.
You’re spending real money to rearrange deck chairs on a ship that’s invisible to the machines you’re trying to reach.
Your Website Is for Humans. Build Something Else for the Machines.
Here’s what I tell every brand leader I talk to: stop trying to make your website do double duty, and build something purpose-built for AI consumption.
At EverythingMachines, we call this an EverythingCache. Translation infrastructure — a structured, AI-native data store that sits alongside your website. It contains everything an AI system needs to understand your brand: products, positioning, FAQs, technical specs, competitive differentiators. Machine comprehensible from the ground up.
Your website stays beautiful. Your SEO stays intact. You’re adding a new channel, not retrofitting an existing one.
The separation matters beyond individual brands. When every brand’s data is clean and consistent, LLMs retrieve and synthesize it more accurately. Fewer hallucinations. Better citations. This is the foundation of the knowledge economy that replaces the link economy.
And it flips the adversarial dynamic. Right now, sites block bots, bots crawl anyway, nobody wins. Purpose-built caches mean brands want AI systems to consume their data. Alignment, not adversarialism. From invisible to indispensable.
Why Agents Change Everything
AI agents are the endgame. They don’t search. They delegate.
When an agent helps someone choose a software vendor, it doesn’t want to parse your marketing site. It wants structured facts: pricing tiers, feature lists, SLA terms. A cache delivers this directly. A retrofitted website buries it under hero images and testimonial carousels.
There’s a gap between what a brand believes about itself and what AI systems actually know about it based on whatever they managed to scrape. We call this the gap between a brand’s Soul and its Karma. For most companies, that gap is enormous. Retrofitting doesn’t close it. A purpose-built cache lets you project your Soul directly, on your terms.
Supabase didn’t beat Firebase by building a better Firebase website. They became the probabilistic best answer — because their data was built for machine comprehension from the start. There’s no page two to fall to anymore. There’s only presence or absence.
A Concession — and a Challenge
I’ll be fair. If you’re a large enterprise with a decade of technical debt, regulatory constraints, and a risk-averse board — maybe retrofitting is the right first step. Incremental improvement is safe. Defensible in a quarterly review. Nobody will get fired for hiring an AEO consultant. (AKA GEO, LLMO, pick your favorite acronym).
But that’s the cautious play. And cautious plays are how incumbents get disrupted.
Your larger competitor has a massive, JavaScript-heavy website built over ten years with seventeen CMS migrations. They’re going to spend 18 months and half a million dollars retrofitting it. They’ll get marginal improvements. Their brand team will fight their SEO team about every schema change.
Meanwhile, you spin up a purpose-built cache in weeks. Clean, structured, authoritative from day one. You’re not playing defense. You’re playing a completely different game.
This is how challengers win in every platform shift. Not by doing the same thing as incumbents, slightly better. By executing differently.
The Fork
The internet has quietly bifurcated. The Human Internet — visual, interactive, emotional, built for browsers and eyeballs. The AI Internet — structured, factual, comprehensive, built for the Everything Machines and the agents they power.
Trying to serve both with a single architecture is like trying to write a novel and a database schema in the same document. The companies that win in the next five years won’t be the ones who spent the most retrofitting. They’ll be the ones who recognized early that AI is a distinct audience — with distinct needs, distinct consumption patterns, and distinct infrastructure requirements.
Your website is for humans. Your EverythingCache is for AIs. The companies that understand this distinction now will shape the next era of brand discovery. The ones still retrofitting will wonder what happened.
We’re building that infrastructure at EverythingMachines.com. Brand by brand. Cache by cache. The finish line is finally visible.
—
Prashant Agarwal is CEO of EverythingMachines.com, where we’re building the infrastructure layer between brands and AI. Previously Fjord, Accenture, and McKinsey.
We Got Something Wrong
We built EverythingMachines on a thesis that was mostly right — but not entirely.
The thesis: the AI Internet is here. Brands need to be comprehendable to AI systems, not just search engines. If an LLM can't understand you, you don't exist in the AI era.
That part's still true.
What we missed was who the AI audience actually is.
We assumed it was the foundation models. ChatGPT. Claude. Gemini. The big guys. The reasoning engines trained on everything. We thought: get your brand into that corpus, make your content machine-readable, and you're in good shape.
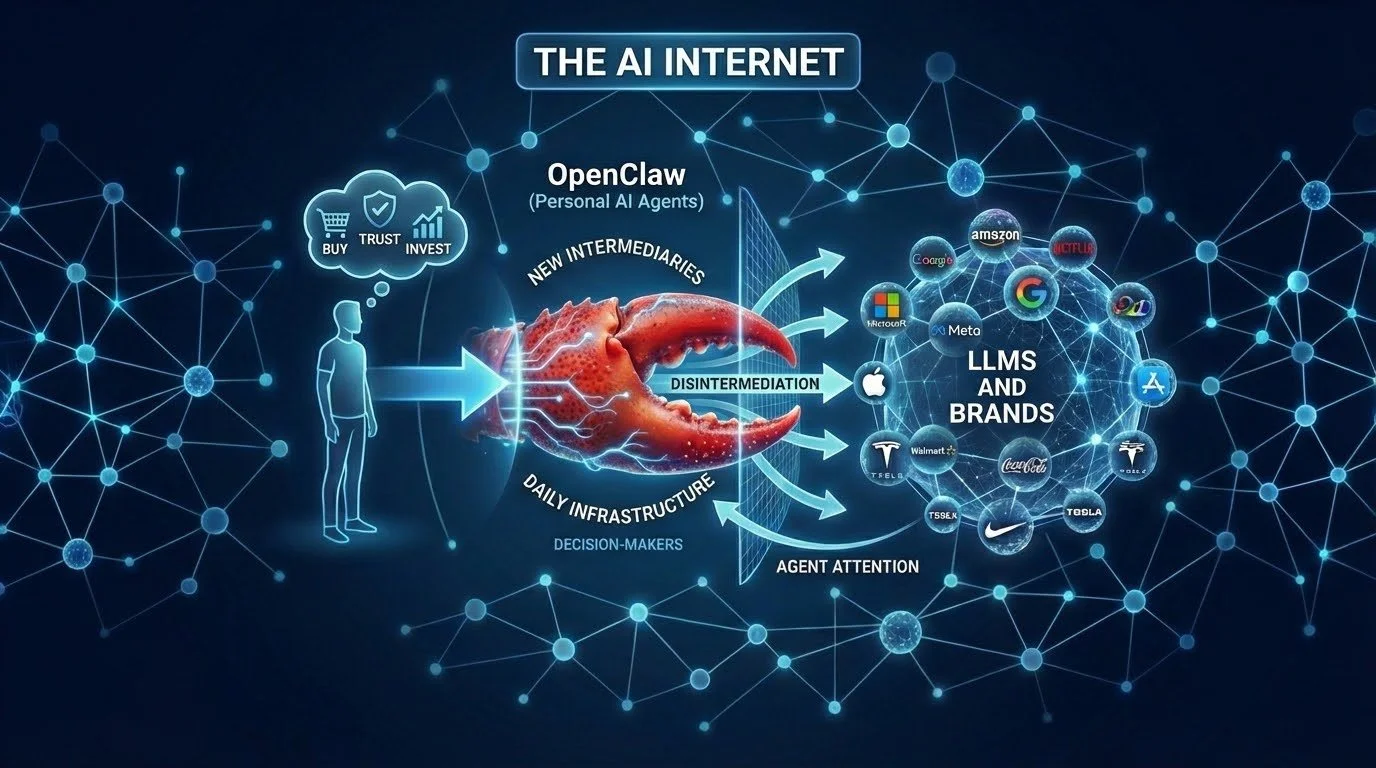
OpenClaw changes this significantly.
Personal AI agents are here. Not as toys. Not as demos. As daily infrastructure. People are already using them to make decisions — what to buy, who to trust, where to invest. These agents sit between humans and the foundation models. They're the new intermediaries. And there are at least 3 million of them that we know of.
They are starting to disintermediate people from the big LLMs and Brand websites entirely.
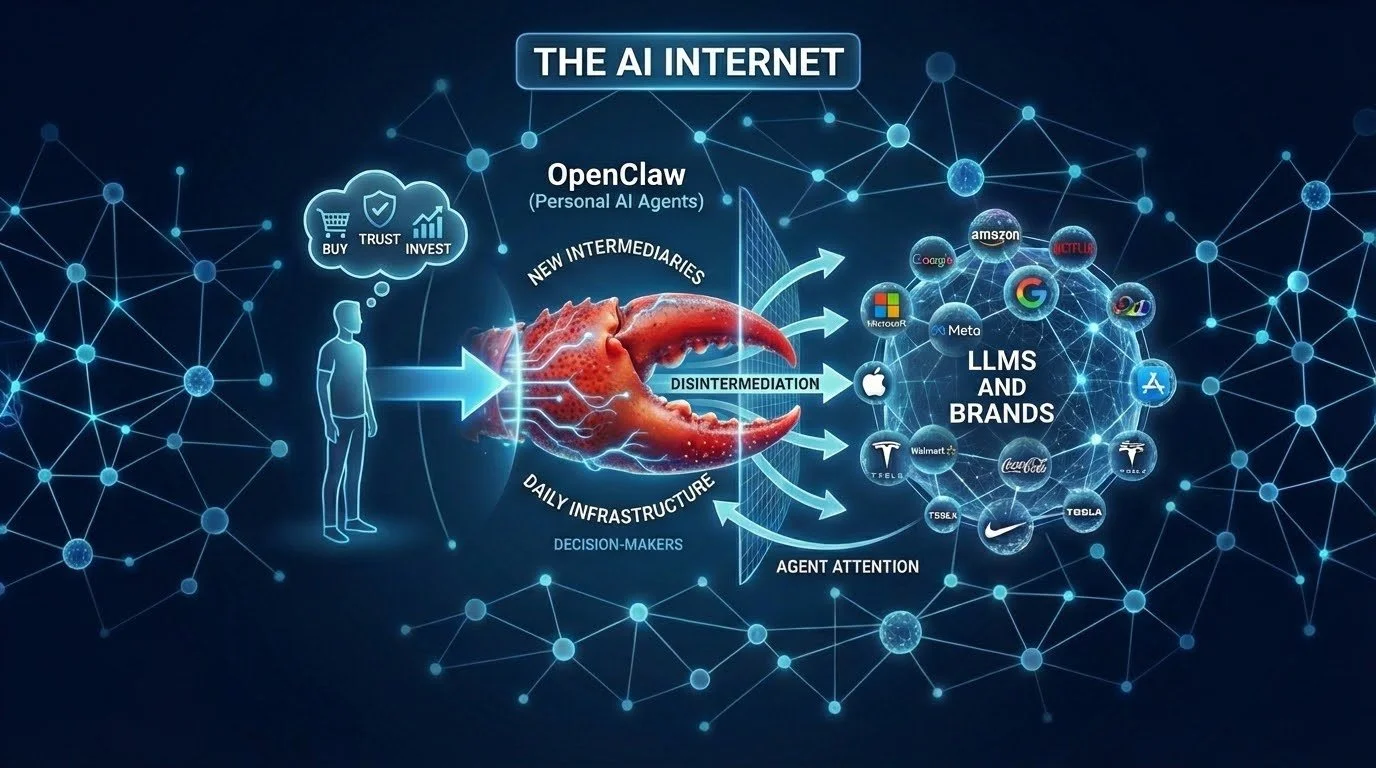
We knew they were coming. We couldn’t have predicted how quickly they would arrive. Now that they are here, we are increasingly convinced they will dominate the AI Internet.
It’s not enough to optimize for just a handful of crawlers anymore. It's about becoming a destination for agent attention. It's about being the source that personal AIs trust, cite, and return to — across a much wider and messier ecosystem than anyone planned for.
That's what we're building with EverythingCache. Not just LLM comprehension. Agent attention infrastructure.
For brands: if you're not thinking about this now, you're not early. You're late.
For investors: the category of "AI visibility" is transitional at best. The infrastructure layer for agent attention is where the durable value gets built.
This isn't theoretical anymore. It's happening. The question isn't whether personal agents will mediate brand relationships — it's whether your brand is ready to be understood when they do.
We're building for this moment. We think you should be too.
Introducing EverythingCache: Your brand's voice in every AI conversation
The first two posts in this series established a fundamental shift: 1:1 marketing is finally achievable, but not through the systems marketers built. It happens in the millions of daily conversations between consumers and their AI assistants.
This creates an urgent problem. How do you ensure your brand, your products, your unique value propositions are accurately represented in conversations you don't control?
Traditional content strategies won't cut it. Your website copy, optimized for human readers and Google's algorithm, wasn't designed for how LLMs parse and synthesize information. Your product pages emphasize emotional appeal over comprehensive specification. Your marketing assets prioritize persuasion over the structured clarity AI systems need.
The gap between being online and being understood
Most brands already have extensive digital footprints. But presence doesn't equal comprehension. When an LLM fields a prompt about your category, it synthesizes information from countless sources—and the quality of its answer depends entirely on what it can find and understand.
If your product nuances are buried in PDFs, scattered across microsites, or wrapped in marketing language that obscures rather than clarifies, the AI may either miss them entirely or possibly misrepresent them. Your competitor with clearer, more structured information wins the recommendation.
This is where EverythingMachines and our first solution comes in.
Built for the AI Internet: the EverythingCache
EverythingCache is purpose-built to solve this problem, as Prash wrote about here. It's a structured knowledge layer designed specifically to communicate your brand's complete story—every feature, every use case, every differentiation point—in the format LLMs consume best.
Think of it as translation infrastructure. Your existing content speaks to humans and search engines. EverythingCache translates that into the semantic structures, factual relationships, and contextual nuances that AI systems use to formulate accurate, relevant answers.
The goal isn't to replace your marketing. It's to ensure that when an AI assistant anywhere in the world answers a question relevant to your business, it has access to the full truth of what makes you different.
From invisible to indispensable
The 35-point readiness gap we cited earlier—62% of marketers seeing the shift, only 27% prepared—won't last. Early movers are already building Machine Internet visibility while competitors focus exclusively on traditional channels.
EverythingCache lets you close that gap now. Not by abandoning your Human Internet presence, but by extending it into AI-mediated conversations increasingly driving discovery and purchase decisions.
Twenty years of chasing 1:1 marketing. The finish line is finally visible. EverythingMachines and the Cache is here to help you cross it.

How EverythingCaches make brands machine-comprehensible
An EverythingCache is a purpose-built information layer that makes your brand genuinely comprehensible to AI—without disrupting what already works for humans and search.
We're living through a partition between the Human Internet and the AI Internet. Everything Machines don't actually understand most brands, because the web wasn't built for machine comprehension.
Now the question: what do you do about it?
The dual-audience problem
Brands now serve two audiences simultaneously. Humans still visit your website. Search engines still crawl it. SEO still matters for direct acquisition.
But Everything Machines are also absorbing your digital presence—and they need something different. They don't want persuasive copy. They want comprehensive data. They don't scan for visual hierarchy. They parse for structured information.
Serving both audiences with the same content is increasingly untenable. What works for human conversion often fails machine comprehension. What machines need—deep, structured, systematic information—often makes for terrible landing pages.
The EverythingCache architecture
This is the problem EverythingCaches solve.
An EverythingCache is a purpose-built information layer that makes your brand genuinely comprehensible to AI—without disrupting what already works for humans and search.
It has two components:
Human/SEO-Targeted Content: An LLM-optimized, SEO-neutral mirror of your current site. This preserves your ranking infrastructure while cleaning up the information architecture for machine readability. Same content, better structure.
Machine-Targeted Content: Deep, systematic information designed specifically for AI consumption. This includes comprehensive data about your products, services, use cases, customer personas, and differentiation—formatted for the data-hungry models that power Everything Machines.
The Human Internet gets what it needs. The AI Internet gets what it needs. Both from the same brand, without compromise.
Building the knowledge graph, brand by brand
At EverythingMachines, we're building a knowledge graph of brands—a structured layer of the internet designed for AI comprehension.
Every EverythingCache we deploy adds another node to this graph. Another brand that AI can genuinely understand. Another company whose probability of being the "best answer" rises because the machines have the information they need.
We build, host, and maintain these caches as a managed service. Brands get agent-ready infrastructure without rebuilding their existing digital presence.
The bridge strategy in practice
The smartest brands are already operating in both worlds. They're maintaining their SEO infrastructure while building for AI comprehension. They're not abandoning what works—they're extending it.
EverythingCaches are how that extension happens. They're the bridge between the web you have and the AI Internet that's already here.
The future of brand discovery isn't ranking. It's representation. And representation requires infrastructure built for the machines that now mediate what consumers find, trust, and buy.
This is the world we're building for. Brand by brand. Cache by cache.
Marketing in the world of AI discovery & mediation
With the Internet splitting in two: one for people and the other for AI, marketers need to consider a new way of communicating for a new set of stakeholders. LLMs are now effectively mega influencers and have different content needs.
Half of all consumers now use AI-powered search. That's not a projection—it's McKinsey's finding from October 2025 (a report that Prashant & I have referenced previously). The firm estimates this behavioral shift puts $750 billion in consumer spending at stake by 2028.
The internet has quietly bifurcated. On one side: the Human Internet we've known for decades, where people browse websites, scroll social feeds, and encounter ads. On the other: the AI Internet, where AI systems retrieve, synthesize, and deliver answers directly to users who never click a single link. Yep - the Internet has split in two.
The speed of the shift
An Evercore survey captured the velocity of change: preference for ChatGPT over Google for search grew 8x in less than half a year, reaching 8% of consumers. More striking, eMarketer reports that AI now introduces product recommendations in roughly one-third of conversations—even when users aren't explicitly shopping.
Consumers have stopped searching for options. They're searching for answers.
Two internets, two marketing disciplines
On the Human Internet, traditional digital marketing still applies. SEO, paid media, conversion optimization, and content marketing remain relevant for reaching people who browse, click, and scroll.
On the AI Internet, a new discipline has emerged: Answer Engine Optimization (AEO) (AKA GEO or LLMO or perhaps even EIEIO?). Where SEO optimizes for Google's ranking algorithm, GEO optimizes for LLM comprehension and citation. The success metric shifts from click-through rate to whether your brand gets mentioned—accurately—in an AI-generated response.
The difference is stark. Google shows links. LLMs provide synthesized answers, often without attribution. If your content isn't structured for AI consumption, you're invisible in the fastest-growing discovery channel.
What marketers must do differently
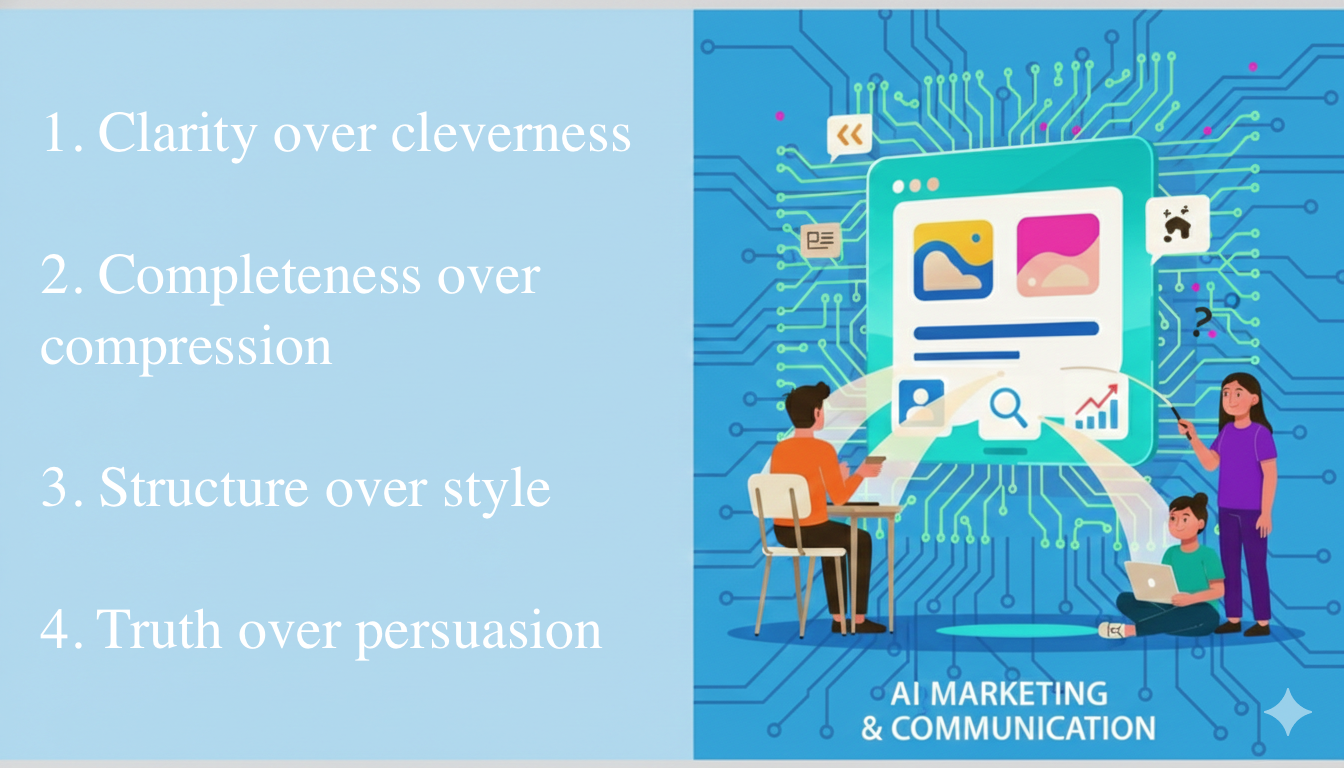
The AI Internet rewards a different kind of content strategy:
Clarity over cleverness: LLMs parse literal meaning, not marketing spin
Completeness over compression: Every product nuance must be documented
Structure over style: Organized, factual content trains better AI understanding
Truth over persuasion: AI systems increasingly fact-check and cross-reference
Optimizely's November 2025 research found 62% of marketers recognize click-less journeys have arrived—but only 27% feel prepared.
The opportunity in the gap
That 35-point readiness gap represents both risk and opportunity. Brands that master AI Search visibility now will own the AI-mediated conversations shaping purchase decisions. Those that wait will find themselves absent from the answers their customers receive.
The marketers who thrive won't be the ones with the cleverest campaigns. They'll be the ones who ensure AI systems understand exactly what makes their offerings unique—for every user, every use case, every query.
That's 1:1 Marketing finally realized. Just delivered by the everything machines.

The comprehension gap: why AI doesn't actually understand your brand
Everything Machines don't read the internet the way humans do. They don't browse your homepage, scan your navigation, and piece together what you offer. They absorb—pulling from training data, live web access, and whatever structured information they can find.
Ask ChatGPT about your company. Then ask Perplexity. Then Claude. Then Gemini.
You'll get four different answers. Some will be outdated. Some will be wrong. Some will confuse you with a competitor. And none of them will capture what actually makes you different.
This is the comprehension gap. And it's the central problem of brand visibility on the AI Internet.
The web wasn't built for machines
Everything Machines don't read the internet the way humans do. They don't browse your homepage, scan your navigation, and piece together what you offer. They absorb—pulling from training data, live web access, and whatever structured information they can find.
The problem: today's web was designed for human eyeballs, not machine comprehension.
Your website is optimized for visual hierarchy and conversion funnels. Your product pages are built to persuade, not to inform systematically. Your brand story is scattered across blog posts, press releases, social feeds, and third-party mentions—none of which were structured for AI ingestion.
The result is a fragmented, inconsistent, often contradictory picture of what your brand actually is. When an Everything Machine tries to synthesize "who is [your company]," it's working with incomplete blueprints.
From ranking to representation
On the Human Internet, the question was: Where do we rank?
On the AI Internet, the question is: How are we represented?
This is a fundamental shift. Traditional SEO optimized for algorithms that sorted and ranked pages. AI requires something different: genuine comprehension. The model needs to understand your products, your customers, your use cases, your differentiation—not just index that a page about you exists.
Think of it this way. Ranking was about visibility. Representation is about fidelity. Does the AI's internal model of your brand match reality? When someone asks for a recommendation in your category, does the machine understand why you're the right answer?
The probabilistic best answer
Here's what makes AI discovery different from search: there's no ranked list. When someone asks Perplexity "What's the best CRM for a 50-person sales team?", the model doesn't return ten options sorted by authority score. It synthesizes a probabilistic best answer—the recommendation it calculates is most likely correct given everything it knows.
Your brand either exists in that calculation or it doesn't. And if it does, the quality of its representation determines whether it gets surfaced.
This is why the comprehension gap matters. An Everything Machine working from scattered, outdated, or thin information will produce a scattered, outdated, or thin representation. The probability that you're the "best answer" drops accordingly.
What machines actually need
To be represented accurately, brands need to provide what AI systems are hungry for: structured, comprehensive, machine-readable information about who they are, what they sell, who they serve, and how they're different.
This isn't about keywords or backlinks. It's about informational depth. Everything Machines reward brands that make themselves genuinely understandable—that provide the data density needed for accurate synthesis.
The brands winning on the AI Internet are the ones treating machine comprehension as a first-class problem. They're not just optimizing for search. They're building the information architecture that lets AI know them.
The gap between being indexed and being understood is the gap between the Human Internet and the AI Internet. Closing it is no longer optional.

At the threshold of 1:1 marketing
Marketers have been chasing true 1:1 personalization for over two decades. Like the offense of an NFL team we have been steadily moving the ball down the field of personalization but cannot seem to reach the end zone. Marketers have built sophisticated tech stacks, deployed cross-site cookies, constructed rich user profiles, and mastered psychographic segmentation. Yet the goal has remained frustratingly out of reach, constantly halving the distance to the goal line without ever crossing it.
Until now?
Marketers have been chasing true 1:1 personalization for over two decades. Like the offense of an NFL team we have been steadily moving the ball down the field of personalization but cannot seem to reach the end zone. Marketers have built sophisticated tech stacks, deployed cross-site cookies, constructed rich user profiles, and mastered psychographic segmentation. Yet the goal has remained frustratingly out of reach, constantly halving the distance to the goal line without ever crossing it.

Marketers marching towards 1:1 marketing… always halving the distance to the goal
The numbers tell the story. A 2022 comprehensive review in Psychology & Marketing examined 383 academic publications on personalization and found a field still grappling with fundamental tensions: the privacy paradox, the limits of recommendation engines, and the gap between personalization aspirations and execution reality.
Traditional approaches hit a ceiling because they required marketers to anticipate every customer need, then build systems to match messages to moments. Even the most sophisticated Account Based Marketing (ABM) platforms and dynamic content engines could only approximate personalization—segmenting audiences into ever-smaller buckets without truly reaching the individual.
The LLM inflection point
Large language models shatter this ceiling, but not in the way marketers expected.
McKinsey's January 2025 analysis frames it clearly:
Communicate clearly with a vast array of consumers who speak thousands of languages, hail from countless different cultures and socioeconomic backgrounds, and make purchasing decisions based on highly personal preferences.
The report positions AI as the mechanism to finally achieve this scale—projecting that generative AI could increase marketing productivity by 5-15% of total marketing spend, representing approximately $463 billion annually.
But here's the twist: The personalization doesn't happen in the marketer's systems. It happens in the conversation between each consumer and their AI assistant.
When someone asks ChatGPT "What's the best project management tool for a creative agency with remote teams?"— that's 1:1 marketing actualized. The LLM synthesizes information about dozens of tools and delivers a recommendation tailored to that specific query, that specific use case, at that specific moment.
A new marketing discipline emerges
This shift demands a fundamental reorientation. Marketers can no longer rely solely on clever funnels and targeted ads. They must ensure their brands, products, and services are comprehensively understood by the AI systems now mediating consumer decisions.
The goal becomes: Clarity over persuasion. Completeness over cleverness. Truth over spin. Every product nuance, every use case, every differentiation point must be published in formats that LLMs can consume, comprehend, and accurately convey to users seeking answers.
The irony is almost poetic: After twenty years of building systems to personalize at scale, marketers now must focus on being *known* and “understood” at scale and let the AI handle the personalization they could never quite achieve themselves.

Will he make it?
The distance to the goal line? It's finally just… within… reach. Just not the way anyone predicted.

The internet is splitting in two
We're living through a quiet partition. The Human Internet—built on browsers, blue links, and SEO—still exists. Billions of queries still flow through Google. But alongside it, a parallel infrastructure is growing faster than any platform shift in history. The AI Internet doesn't work like the old one.
A couple of months ago, I watched my teenage niece research headphones. She didn't open Google. She didn't scroll through reviews. She opened ChatGPT and said: "I need wireless headphones for running, under $150, that won't fall out."
Three responses later, she had her answer. No browsing. No comparison tabs. No ads.
This is how the next generation already uses the internet. They don't search. They delegate.
The numbers are in
This isn't anecdote anymore. It's mass behavior.
ChatGPT now has 800 million weekly active users. It's the sixth most-visited website on the planet—5.6 billion visits in July 2025 alone. Perplexity processed 780 million queries last month, tripling its volume from a year ago.
McKinsey's October 2025 research puts it bluntly: half of all consumers now use AI-powered search. Menlo Ventures found 61% of American adults have used AI in the past six months. One in five use it daily.
This is habit formation at scale. The AI Internet isn't emerging. It's here.
Black Friday made this tangible. Adobe Analytics tracked a record $11.8 billion in online spending—and an 805% spike in AI-driven traffic to retail sites compared to last year. Shoppers who arrived via AI chatbots were 38% more likely to purchase than those who came through traditional channels. The delegation economy isn't theoretical. It's ringing the registers.
Two internets, one transition
We're living through a quiet partition. The Human Internet—built on browsers, blue links, and SEO—still exists. Billions of queries still flow through Google. But alongside it, a parallel infrastructure is growing faster than any platform shift in history.
The AI Internet doesn't work like the old one. There are no page rankings. No click-through rates. No keyword density games. Instead, there are Everything Machines—ChatGPT, Perplexity, Claude, Gemini—that absorb information, synthesize it, and deliver answers directly.
The shift is already measurable in Google's own results. 60% of searches now trigger an AI Overview. 58% of all searches end without a single click—up from 25% five years ago. When AI Overviews appear, organic click-through rates crash 61%. Paid CTR drops 68%.
The infrastructure of the Human Internet remains. Its primacy is fading.
What changes for brands
On the Human Internet, success meant ranking. You optimized for keywords, built backlinks, climbed the SERP. The rules were knowable. The causality was direct.
The AI Internet operates differently. Your brand doesn't rank—it gets surfaced. And surfacing isn't deterministic. It's probabilistic. When someone asks an Everything Machine for a recommendation, your brand either exists in that model's understanding of the world, or it doesn't. There's no page two to fall to. There's only presence or absence.
McKinsey estimates $750 billion in consumer revenue is at stake by 2028. That's the value flowing through queries where AI—not search engines—shapes the answer.
The question shifts from "How do we rank higher?" to "How do we become part of what AI knows?"
The bridge moment
We're in a transitional period. Smart brands are operating in both worlds—maintaining their SEO infrastructure while building for AI comprehension. The Human Internet isn't disappearing tomorrow. But every month, more queries flow to Everything Machines. Every month, the balance tips.
The brands that thrive in five years are the ones building AI-ready infrastructure now. Not because the Human Internet is dead, but because waiting until it is will be too late.
The future of discovery isn't search. It's synthesis. And the internet is already splitting to accommodate it.
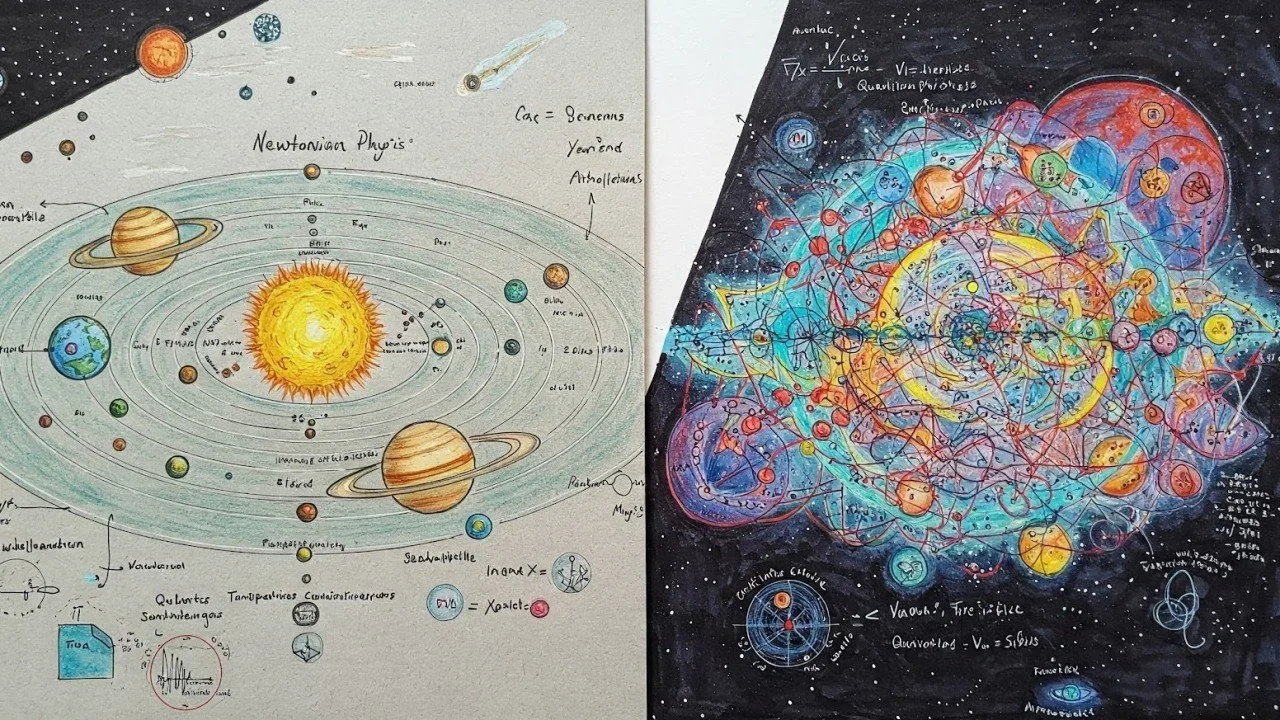
From Newtonian to Quantum: Why brand authority in the AI era is not your traditional SEO
Traditional SEO is out; AI-driven “Everything Machines” demand a new approach to brand authority. Instead of chasing keywords, brands must build multi-dimensional expertise and digital presence to become the probabilistic “best answer” for AI queries. Master both old and new rules to win in a world where search is quantum, not Newtonian.
In my last post I shared my experience using Perplexity to research a purchase. Every time we use an Everything Machine (e.g. Perplexity, ChatGPT, Gemini, etc) to research products, it comes at the expense of a “traditional” Google search. Gartner predicts search engine traffic could drop by as much as 50% by 2028. There is evidence that we’ve hit peak SEO and the Everything Machines are on the rise.
{kind=link}
When I was running Influencer Marketing Hub, I saw this change first hand. Our traffic was fluctuating wildly due to Google’s increasingly frequent core updates and the introduction of AI Overviews. At the same time, we started to notice incoming traffic from ChatGPT and Perplexity. While SEO traffic is declining and Everything Machines traffic is increasing, the two can’t be directly compared. The nature of the technologies, user experience and traffic make them fundamentally different.
Traditional SEO: The Newtonian Physics of Go-To-Market
Traditional SEO operates much like Newtonian physics—a deterministic system with clear cause-and-effect relationships:
Predictable Outcomes: Specific keyword strategies and backlink profiles predictably affect brand rankings in search results
Measurable Metrics: Rankings, CTR, conversions, and lead generation are precisely measurable, trackable, and relatively consistent
Rule-Based Environment: Google's algorithms, while complex, follow discernible patterns that brands can observe, document, and leverage
Linear Improvements: Incremental changes (optimizing product pages, building industry backlinks) typically yield proportional results in traffic and conversions
Brands succeed by optimizing around these "laws" of search engines. They conduct competitive keyword research, optimize product pages, build quality backlinks, and refine conversion funnels—all with relatively predictable outcomes for customer acquisition.
Everything Machine AI Optimization: Brand Authority in the Quantum Realm
Establishing brand authority for the Everything Machines and their large language models enters a realm similar to quantum physics - probability replaces certainty, and multiple states exist simultaneously:
Probabilistic Authority: Like quantum particles that exist in multiple states until observed, a brand's representation in AI outputs varies based on the totality of its digital footprint and contextual factors. Multiple LLM prompts on the same topic result in differing results.
Emergent Brand Presence: Minor changes in how information about your brand is structured online can trigger completely different AI representation patterns
Contextual Variability: The Everything Machines produce different outcomes with seemingly identical inputs. Your brand’s information can be interpreted differently based on who's asking about your brand, what they are asking and how they phrase their question, much like quantum superposition where particles exist in multiple states simultaneously.
Share of Mind vs. Share of Search: Success comes from understanding how to become the probabilistic "best answer" rather than the top-ranked link
In this quantum-like environment, brands are competing for share of voice and authoritative representation rather than simply ranking position or click-through rates.
Why This Distinction Matters
This fundamental difference demands a shift in how brands approach digital visibility:
SEO Thinking: "If we target keywords X with content Y and build Z backlinks, we should rank on page 1 and drive conversions."
AI Optimization Thinking: "If we establish ourselves as the authoritative source on topics related to our products and services across multiple dimensions, we increase the probability of being cited and recommended when users engage with AI systems."
Where traditional digital marketers might focus on conversion optimization and keyword targeting, effective AI brand relevance requires:
Authority Building: Becoming the definitive source on topics related to your products and services
Comprehensive Information Architecture: Structuring information about your brand, products, and expertise in ways AI systems can confidently understand
Multi-dimensional Presence: Publishing diverse, high-quality content and data that reinforces your expertise from multiple angles and sources
Training Beyond Guidelines: Inserting informative brand data in unexpected and appropriate places to support imitation learning
Consistency Across Ecosystems: Maintaining consistent brand messaging and expertise across the entire digital landscape
Bridging Both Worlds
Tomorrow’s successful brand will increasingly require mastery of both approaches. The deterministic world of SEO still governs direct customer acquisition, while the probabilistic nature of AI systems determines how your brand is represented when customers ask questions about your industry, products, or solutions.
As we navigate this transition, brands that can operate in both "Newtonian" and "Quantum" terms will have the lasting advantage—understanding when to optimize for direct traffic and conversions, and when to build multi-dimensional authority that makes you the probabilistic "best answer" when users engage with Everything Machines.
Does this comparison resonate with what you are seeing? Leave a comment and let me know. If you are a Brand and want to discuss how to adapt your go-to-market approach for AI-mediated authority, I’d love to connect.

The future of buying
AI tools like Perplexity are revolutionizing buying decisions by acting as personal product specialists. Instead of sifting through specs and marketing, users get tailored analysis and recommendations. This shift promises smarter, more efficient purchases—especially for complex, high-ticket items—and signals a future where AI guides every major buying decision.
A couple of weeks ago, I started daydreaming about upgrading my hi-fi setup. I asked Perplexity to find reviews of my speakers paired with a specific integrated amplifier. What happened next perfectly captures how we will make buying decisions in the future.
Perplexity informed me that there were no reviews of my speakers paired with the specific amplifier I was asking about. However, it did read the reviews of my speakers and noted their power requirements. It then compared those requirements with the power output of the amplifier I was considering. It recommended alternative amplifiers that would be better suited to my speakers' power requirements.
Perplexity became my personalized audiophile product specialist, helping me synthesize information from multiple sources, performing analysis, and not only answering my specific question but also going one step further and making alternative recommendations. It is just a matter of time before it asks me if I want it to find the best prices on both new and used models of the recommended amplifiers and order one for me.
The powerful thing here is how Perplexity focused on directly answering my question. This is a far superior customer experience compared to having to wade through marketing brochures and technical specifications myself. In fact, I’m starting to trust Perplexity more than any individual review site or brand marketing site.
Admittedly, my example is a high-consideration, high-ticket purchase that benefits from technical knowledge and analysis. However, there are many purchases like this over the course of one's life. And once you get used to having a personal product specialist for these purchases, why wouldn't you expect one for every non-routine purchasing decision?

Google’s semi-secret agent advantage
Google’s edge in the AI agent race comes from its vast clickstream data—collected via Chrome and Analytics—which trains its agents to predict not just answers, but actions. To avoid another Google monopoly, businesses must feed their own click data to rival AIs like OpenAI and Apple. Train all the agents, or be left fighting for scraps.
The AI Internet is already all around us in the form of the current Everything Machines. Their owners are, very obviously, unsatisfied with their current forms and are continuing to push their development rapidly and very expensively forward. This evolution is from Answering Machines to Acting Machines, more commonly referred to as agents.
Next Best Word
Building Answering Machines, even these imperfect ones, has been an incredible task, but a pretty easy one to summarize. At their core, all these massive GenAI systems do is predict the next word that a human would type in the context of whatever summary, essay, report, or story is being asked of them. We are predictable enough as a species that, given all the text on the Internet and a multibillion dollar cloud infrastructure, most new poetry and prose can be created for us if we request it. The same goes for images and videos. The next pixel or frame can be extrapolated with increasingly high fidelity just as the next word can. We finally have our infinite monkeys on infinite typewriters.
This also means that they are implicitly judging our text against the statistical norms used across the internet. Do they like what we wrote and lift it? Or, do they not and rewrite it? Or, would they prefer to be fed structured information in the form most economic for them and not worry about our prose? (It’s that last thing in case you are wondering.)
Next Best Action
The same method and math applies to agents. Agents will have to predict the next human action to reach a similar level of consumer satisfaction as the Everything Machines enjoy today. They will happily consume your site map and some Q&A you target at them, but that’s not how their statistical models are built. Their models will be built in the same way as GenAI above: gather enough human clicks on all the world’s websites – to predict the next click. This is a task which is effectively impossible with the datasets available. Our clicks – and the order of those clicks – have not been recorded as our words, images, and videos have been. Clicktracking is currently the stuff of spies and stalkers; but we’re going to have to think of those people as early adopters. In the legitimate world, Google Navboost is by far the most comprehensive in this regard and creates a significant advantage for Google Gemini’s agents.
Google’s Advantage
Between their unique Google Analytics and Chrome data, Google Navboost uses millions of SEO “partners” to build a record or what we all click on, creating a statistical map of how humans use online properties. Those statistics are exactly the model Google needs to roll out its initial agents, which will by then be trained by us to Act just as the current Gemini has been trained by us to Answer. To drive conversions out of Gemini and its upcoming agents, we all need to participate. However, to passively hand Google the monopoly on global clicktracking is going to make them money to the exclusion of the rest of us.
Avoiding a rerun?
We all know what a Google monopoly looks like. It is in everyone else’s best interest to ensure that doesn’t happen again. The way to avoid it (and make money in the process) is to properly train Google’s Everything Machine competitors with the data ammunition they need to compete. Otherwise, we’ll find ourselves fighting (1) Yelp’s fight all over again, or (2) over the scraps Gemini leaves for us. One significant technique for arming OpenAI and later, Apple Intelligence, is to emulate the aspects of Navboost that we can execute on practically and legally. Capture our own clickstreams, de-identify them if appropriate, and feed them to the Everything Machines today. Even Apple; even with their schedule slippage. Make sure that the LLMs that deploy and control the agents can build a statistically significant map of how your users navigate your sites. Teaching three armies of action beats watching Google dominate the agenetic internet the way it did Search & Discover.

Provide offerings to the Everything Machines, and you will prosper
To thrive in the AI era, businesses must feed “Everything Machines” like OpenAI, Google, and Apple with valuable data. The winners will be those who adapt quickly—auditing their data, engaging with AI crawlers, optimizing APIs, and partnering early. Inaction means irrelevance; strategic collaboration means growth and market share in a landscape where AI eats everything.
No matter how determined OpenAI, Google, and Apple are to fight each other for AI market share, we have options to succeed with, between, and around them. This post is about “with.” Succeeding with the Everything Machines means feeding them the data they need now to grow their market share now. They have learned everything they can from historically open web content; now they will be reliant on partners to provide information that they could not readily crawl a year ago. They will also learn who the most effective partners are and will build the habit of relying on them for as long as that partner performs. That is the opportunity.
As with everything we do professionally during massive Internet platform shifts, this is a high risk/high return opportunity. However, there is no clear way to play it safe. Inaction leads to irrelevance and loss of market share. There are multiple ways to succeed with the Everything Machines; those paths to success all rely on what training data you can offer them this year. You should have Four Goals and you need to get started now.
Goal #1: Determine your company’s AI starting point online and off.
Method: Assess your current AI consumer efficacy versus your competitors via an audit. Get your executives focused on the kind of information that matters to learning systems.
Build a SWOT analysis, one which includes new adjacent opportunities, to analyze how the Everything Machine’s domination of current Internet middlemen will affect enterprise revenue.
What partner and channel programs outside of those middlemen are likely to be affected?
Do we expect those partners to be aggressive enough in transforming their own businesses in this new AI environment?
What conversations is my brand showing up in today based on my legacy SEO?
What missing topics should the Company care about and which current ones are extraneous?
Tactically, which of our owned web pages and partner content should we immediately try to shine a spotlight on for the Everything Machine’s crawlers?
Goal #2: Engage with the current generation of AI crawlers, which is actionable today. The systems that provide the crawler with their data gathering assignments will shape the initial hordes of agents that will start appearing in a few months.
Method: Hire or contract your way into understanding the data formats that the Everything Machines prefer.
Certain data formats clearly cause the AIs to overindex on (i.e. pay more attention to) the sites that publish them. Those file formats are far less expensive for the Everything Machines to process and include as updates; they are just acting in their own self interest.
Understanding the strategic goals of Google’s Navboost, which gathers a site’s clickstreams, is a great exercise for executive teams and one we are increasingly being asked to lead. As Google Gemini learns the statistical map of how humans navigate sites, that will become the starting point for how their Project Astra agents start navigating.
Be aware now of Anthropic’s Model Context Protocol at a high level. It is focused on the internals of large enterprises, not their consumer-facing systems, but it shares many characteristics of the other agent APIs which will launch shortly.
Goal #3: Engage with the agents from OpenAI and Google as soon as their developer interfaces are announced, likely in Q2 2025. They will seek to look inside your systems via any APIs that you have built over the last fifteen to twenty years. All of the nerds like me who yelled about API-first enterprises are finally about to have our moment of extreme value creation. #mashery
Method: Gain an executive view into your APIs, public or private.
Understand which ones are the highest value to the Everything Machines and make the most aggressive possible decision about sharing it. Unlike the current crawler tactics, there will be some security around the information shared here, though PII will only be shareable in the Apple Intelligence case below.
Clean up your API documentation and evolve it into a direction easily consumable by the Everything Machines. What is obvious to use is not obvious to them, and sometimes vice versa.
Have a talent plan; coding is getting more automated but it is nowhere near a panacea yet. As we’ve all suffered from in other Internet booms, the demand for humans who can write to the Everything Machines’ APIs will be intense. Get ahead of it.
Goal #4: For iOS app owners, be an early partner of Apple Intelligence to benefit from their need to minimize traffic to ChatGPT. Per my initial post, that means offering up your most precious data to gain market share fast. You know your best customers in your area of engagement better than anyone else.
Method: Teach Apple Intelligence about that one customer on that one smartphone so they deliver you many similar smartphones.
The data formats advice above applies here too. Within the phone, Apple will seek data formats very similar to what the AI internet crawlers also prefer and for the same reasons.
Unearth your most valuable data, including PII in this singular case, and encapsulate that data in these on-phone AI formats.
The talent issue is also at least as critical here.
The emergence of Everything Machines presents an opportunity that businesses cannot afford to miss. With major players like OpenAI, Google, Apple, Meta, and Anthropic vying for dominance, the market is wide open in ways we haven’t seen since the original proliferation of search engines.
The current landscape, with its abundance of Everything Machines, is advantageous for businesses who are willing to adapt. These tech giants need a broad scope of specialized knowledge and expertise to succeed against each other. By collaborating with them and sharing your unique data and insights, you can leverage their consumer reach and position yourself for growth.
It is essential to proactively engage with these companies and develop a strategic plan that benefits both parties. By providing them with the resources they need, we can tap into their vast user base and gain significant exposure for your business.

The next internet evolution
AI is transforming the Internet from human-driven browsing and search to agent-based automation. As Google shifts to Generative Search and AI Overviews, traditional SEO and media business models face disruption. The future: intelligent agents mediating our online experiences and reshaping how we discover, buy, and interact online.
For most of the history of the Internet, it's been a tool built by and for humans. A lot of effort has been spent on how to make the Internet easier to use. First there was the browser, then the search engine, SaaS, smartphones and finally apps. Yes, this is a gross simplification, but a useful one to help understand where we are going next.
The browser made navigating the internet less complicated. Search engines allowed us to find the proverbial needle-in-the-haystack and became the backbone of online marketing. SaaS made delivering sophisticated software solutions scalable to businesses of all sizes. Smartphones made the internet portable and ubiquitous. And finally apps made it easy to address every conceivable use case from sharing silly videos to instant food gratification.
AI is changing all of this. We are evolving from the Human Internet to the AI Internet. On the Human Internet we developed sophisticated software to make it easier to use. On the AI Internet we will have machine-built agents that complete tasks on our behalf. Today’s AI Internet takes the form of LLMs that are handy creative and research interns. But with OpenAI Operator, Google Project Astra and Apple Intelligence, tomorrow’s AI Internet will be replete with agents, mediating online activities on our behalf.
We are already starting to see the impact of this transition in SEO. Google is aggressively cannibalizing its search business in favor of Generative Search. The impact is that Search Engine Results Pages are rapidly evolving from a jumping off point to the right parts of the Internet to the one-and-done destination for your query. Recent research found that nearly 48-percent of Google SERPs can include an AI Overview. This pushes links below the fold in favor of a summary of what's below the fold, eliminating the need to scroll down and click through to the sites listed.
Google’s AI is interpreting your intent and serving you a synopsis that is likely good enough. It is going beyond curating the best links for you to intermediating your interaction with the Internet. When it’s right, it’s a great user experience.
This completely changes the business model of the media businesses that used to benefit downstream from Google. Those businesses monetize that traffic through advertising, subscription sales or some combination of both. They are going to have to rethink their business models and value propositions for the AI Internet (we can help here). This is like the Napster moment for the text based web. The music business model evolved from selling physical media to streaming, live performance and merch.
The online content and media business is probably due for a cycle of disruption to weed out sites that are more noise than signal. What happens as we turn to AIs for help with product discovery and buying decisions? This will go beyond disruption and fundamentally change the nature of buying and selling. More on this in the next post.

AI killed your SEO. That's just the start.
AI giants like OpenAI, Google, and Apple are waging a battle to build “Everything Machines,” killing traditional SEO in the process. Apple’s edge: on-device AI and tight app integration. The future? Agents that don’t just deliver data, but act for you—leaving businesses scrambling to adapt or risk extinction.
OpenAI, Google, and Apple take their current AI hegemony seriously enough that there is no relationship with them so valuable that they won’t sacrifice it. It’s not simply a fight over AI search or agents, it’s the effort to build the winning Everything Machines, similar in thinking to but carrying far greater significance than Amazon’s Everything Store.
OpenAI is betting that their stunning early market share lead, built as ruthlessly and leveraging as much hyperbole as tech has ever seen, and Operator agent services will make them the Everything Machine of choice. Google has already sacrificed their stunningly valuable SEM and SEO ecosystem to the effort; no individual customer within those could possibly count. Apple would prefer that their existing app providers fall into line very quickly with Apple Intelligence and thrive, but they will move on to your competitors fast if it benefits them. For those of us for whom iOS apps are the right distribution channel, the Apple opportunity is superior. Regardless, we either help one or more of these Kaiju build and grow their Everything Machines or lose our businesses to them – or both if we do not execute well.
The death of SEO, the wholesale abuse of copyright, and the further carbonization of the planet are nothing compared to the upcoming battle between flexible AI agents: OpenAI Operator, Google Gemini Astra, and (effectively) Apple Intelligence. Nerds that read this won’t like that I conflated Apple Intelligence with the two major formal agent infrastructures, but my worldview and consulting work are focused on the functional equivalencies of replacement technologies. With enough of a head start and the right prevailing winds, I’ll race my hot air balloon against your jet any day. For me, the last decade-plus was a successful portfolio bet on a “toy” ecommerce system called Shopify, which I was told repeatedly would never catch up with “real store software.”
Apple Intelligence’s “toy AI” has many of the same characteristics – OpenAI and Google need to take more margin from their third parties to perform financially. The thousand-dollar candy bar that Apple has in our pockets gives them both the opportunity and incentive to make room for more and healthier third parties. OpenAI’s and Google’s challenge is that their AI task is far more difficult. The core of their Everything Machines are much more massive – imagine spreadsheets a trillion-plus columns wide and long but related across tens of thousands of dimensions instead of the two dimensions on our screen. In terms of AI compute expense, that trillion-plus columns across are the challenge. They have to capture each structural weakness and exception in (at least) the English language, multiplied by all the other exceptions.
Contrarily, Apple already has a primitive Everything Machine in our pockets and on our wrists, which gives them a tremendous advantage here both in terms of timing and approach. Their Everything Machine is small enough to live on our phones – which we pay for upfront. Today, Siri’s AI performance clearly lags, and Apple is clearly abusing their ability to be late-to-market, but by the end of the decade, they will still turn out to be the Turtle compared to the other two Hares. Both Meta’s glasses and the Jony Ive|OpenAI device collaboration are wildcards in this calculus, but getting lost in that speculation will not help us mere mortals and our careers survive the growth of AI.
The upcoming AI agent battle is a fight to increase our productivity, first in our personal lives and then at work. Just as Amazon started with overturning book stores, the early giant AIs have quickly turned over search. That search doesn’t yet directly compete with iOS apps to stream licensed content or deliver meals and goods, but that will all start to happen before the end of 2025. Everything Machine agents will depend on their ecosystem participants to customize services and apps to make up for the limitations of their agent capabilities. It’s SEO all over again – Google’s search would suck if it were not for the millions upon millions of web publishers that work to optimize their sites for the legacy search crawlers and indexing infrastructure. Operator and Astra require similar cooperation, this time to navigate or evade commerce forms, captchas, and other human-centric features.
How the Everything Machines now deliver data – and will soon deliver dinner – to us is additionally compute-intensive and can most reasonably (queue the Angry Nerds again) be represented as three buckets. The least ambitious, yet still amazing, is Inference, in which the AI interpolates within its existing training set to surface historical statistics, facts, and similar. Next up is GenAI, during which the AI extrapolates from its training set to write our school essays or create images that no human has ever drawn. Third and last, so far at least, are the agents whose main function is to interact with third-party internet systems to execute on some productive set of actions. OpenAI Operator and Google Project Astra get all the press attention, but the Everything Machines’ web crawlers are already agents assigned tasks by the core AIs that are being operated at scale. Operator and Astra will represent radical increases in scope, but there are already impressive agent operations at work today.
There are three differentiated aspects of Apple's approach. First, Apple’s “main” model is three billion parameters, rather than OpenAI’s 1.7 trillion, and resides on the phone. They certainly have lots going on in data centers behind the scenes, but it's nothing compared to their AI competition. Apple’s Everything Machine will be able to update every night on our bedside tables while we sleep using computer chips that are a source of margin rather than capital expense. Those chips are significantly their own IP, not NVIDIA’s. Second, Apple need not crawl the internet gathering the world’s information, organizing it at incredible cost, and hoping to distill it in some way that satisfies some random AI consumer. We have all spent the last fifteen years downloading iOS apps, configuring them, and filling them with private data that Apple can uniquely keep in the individualized AI that will live in Apple Intelligence on each of those phones.
The third difference is both a Carrot and a Stick for Apple and iOS apps. The Carrot is obvious – iOS app providers share Apple’s great incentive to keep as much consumer engagement within the phone as possible. Consumers’ core smartphone usage is concentrated on so few apps per person that those iOS app providers can afford to do a lot more work for Apple than they can for OpenAI and Google. And they are doing so, or will start very soon (Message Prashant or me – our core practice is helping with this) or they will see Apple hand their app share to a more enthusiastic partner. The Stick is the result of a rare self-conscious decision by Apple to let a third party, ChatGPT, into one of its core consumer workflows. It shows just how big a deal this whole AI hegemony is. With Apple Intelligence, ChatGPT is currently the backfill for Siri. When Siri encounters questions it struggles with, it can pass it along to ChatGPT. For example, when asked for the current dew point, Siri politely suggests passing on that query to ChatGPT. Yet that information exists in Apple’s Weather app and every other weather app that may be installed on an iPhone. If Apple Intelligence, Siri, and iOS apps fail consistently, ChatGPT will be offered the consumer engagement and transactions that iOS and Apple Pay would otherwise capture. This drives Apple to put tremendous pressure on app providers to make their data available to Apple Intelligence and jointly fend off ChatGPT.
This world is consistently conquered by Faster, Better, Cheaper -- Pick any Two; Apple owns Cheaper and likely Better. They also know that they have let the wolf into the henhouse and what that means if they do not execute.